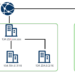
SQLのJOINで利用される代表的な結合方法にはNested loop join(NLJ、ネステッドループ結合)、Merge join(マージ結合、ソートマージ)、Hash join(ハッシュ結合、ハッシュ値マッチング)の3種類があります。1 2
このうちNested loop joinはJOINの最も基本的なアルゴリズムで、多くのRDBMSで利用可能です。
今回はインデックスを活用したNested loop joinの高速化について紹介します。
MySQLは5.7.34を利用しています。
目次
Nested loop joinのしくみについて
Nested loop joinを利用したテーブルの結合の手順は以下の通りです。
- 外側テーブルのレコードを1行ずつ取り出す
- 取り出されたレコードと結合可能なレコードを内側テーブルから検索する
1行ずつレコードが取り出される外側テーブルのことを『駆動表(外表、外部表)』、結合対象のレコードが検索される内側テーブルのことを『内部表(内表)』と呼びます。
Nested loop joinの流れを図で表現すると以下のようになります。

駆動表のレコード数をm、内部表のレコード数をnとした場合、Nested loop joinでは単純計算するとm x n回レコードの結合検証が行われます。
Nested loop joinを高速化するアプローチ
Nested loop joinを高速化するには2つのアプローチが考えられます。
- 結合対象のレコードを事前に絞りこみ、駆動表のレコード数mと内部表のレコード数nの値を減らす
- インデックスを有効にし、検索でフルテーブルスキャンしないようにする
前者はSQL自体を改善するアプローチです。
WHEREなどで結合対象のレコード数を絞り込むことで結合検証の回数(m x n)を減らし、Nested loop joinの高速化を図ります。
今回は後者のインデックスを活用したNested loop joinの高速化について紹介します。
インデックスを利用したNested loop joinの高速化
Nested loop joinの処理の中でインデックスによる高速化が期待できる箇所は以下の2点です。
- 駆動表から結合対象のレコードを検索するとき
- 結合条件を満たす内部表のレコードを検索するとき
駆動表にインデックスを作成することで、結合対象を検索する際に駆動表のフルテーブルスキャンが不要になります。イメージ図は以下の通りです。

内部表にインデックスを作成することで、結合時に駆動表1レコードごとで行っていた内部表のフルテーブルスキャンが不要になります。イメージ図は以下の通りです。

インデックスによるNested loop joinのチューニング例
1対多で紐づくusersテーブルとbooksテーブルを結合し、userのageが30のbooksレコードを取得するSQLをチューニングしてみます。
説明の便宜上、STRAIGHT_JOINを利用してusersテーブルを駆動表、booksテーブルを内部表に固定しています。
SELECT STRAIGHT_JOIN b.* FROM users u, books b WHERE u.id = b.user_id AND u.age = 30;
なお、usersテーブルおよびbooksテーブルにはPrimary key以外にインデックスは作成されていないとします。
インデックス作成前
インデックスが作成されていない場合、EXPLAINの結果は以下のようになります。
JOINの場合は駆動表、内部表の順番でEXPLAINに表示されるため、今回の場合はusersテーブルが駆動表、booksテーブルが内部表となります。
> EXPLAIN SELECT STRAIGHT_JOIN b.* FROM users u, books b WHERE u.id = b.user_id AND u.age = 30\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: u
partitions: NULL
type: ALL
possible_keys: PRIMARY
key: NULL
key_len: NULL
ref: NULL
rows: 996364
filtered: 10.00
Extra: Using where
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: b
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 2980163
filtered: 10.00
Extra: Using where; Using join buffer (Block Nested Loop)
2 rows in set, 1 warning (0.00 sec)
1. rowは駆動表から結合対象のレコードを検索するクエリ、2. rowは結合条件を満たす内部表のレコードを検索するクエリです。
typeに表示されているALLはフルテーブルスキャンが実行されていることを意味します。
typeにALLが表示されるクエリは改善が必要です。
keyがNULLなので当該クエリではインデックスは利用されていないことがわかります。
EXPLAINの読み方の詳細解説はMySQLのEXPLAINの読み方とチューニング時のチェックポイントで紹介しています。
結合対象のレコード検索の高速化
検索条件はu.age = 30ですので、usersテーブルのageに対してインデックスを作成すれば駆動表のフルテーブルスキャンをせずに済みます。
usersテーブルのageにインデックスを作成後、再度EXPLAINを実行すると結果は以下のようになります。
> EXPLAIN SELECT STRAIGHT_JOIN b.* FROM users u, books b WHERE u.id = b.user_id AND u.age = 30\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: u
partitions: NULL
type: ref
possible_keys: PRIMARY,index_users_on_age
key: index_users_on_age
key_len: 5
ref: const
rows: 22196
filtered: 100.00
Extra: Using index
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: b
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 2980163
filtered: 10.00
Extra: Using where; Using join buffer (Block Nested Loop)
2 rows in set, 1 warning (0.00 sec)
駆動表のレコードの絞り込みをする1. rowのクエリにおいて、keyにindex_users_on_ageが表示されたので、インデックスが利用されていることがわかります。
インデックスが利用されるようになったため、1番目のクエリのtypeがALLからref(ユニークではないインデックスによる等価検索)に変更されました。
結合条件を満たすレコード検索の高速化
結合条件はu.id = b.user_idですので、booksテーブルのuser_idに対してインデックスを作成すれば内部表のフルテーブルスキャンをせずに済みます。
booksテーブルのuser_idにインデックスを作成後、再度EXPLAINを実行すると結果は以下のようになります。
> EXPLAIN SELECT STRAIGHT_JOIN b.* FROM users u, books b WHERE u.id = b.user_id AND u.age = 30\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: u
partitions: NULL
type: ref
possible_keys: PRIMARY,index_users_on_age
key: index_users_on_age
key_len: 5
ref: const
rows: 22196
filtered: 100.00
Extra: Using index
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: b
partitions: NULL
type: ref
possible_keys: index_books_on_user_id
key: index_books_on_user_id
key_len: 5
ref: rails6_api_mysql8_development.u.id
rows: 3
filtered: 100.00
Extra: Using index condition
2 rows in set, 1 warning (0.00 sec)
結合条件でインデックスが利用されるようになったため、2番目のクエリのtypeがALLからrefにかわりました。
まとめ
- SQLを改善し、駆動表と内部表のレコードの組み合わせ数を減らす
- 結合条件で利用するカラムにインデックスを作成する
- 検索条件で利用するカラムにインデックスを作成する
Twitter(@nishina555)やってます。フォローしてもらえるとうれしいです!