個人ブログの初期設定をするときにSEO対策をすると思います。
SEO対策をするにあたり、「クローラー」、「サイトマップ」、「robots.txt」などの言葉をよく聞くと思いますが、以下のような疑問を持つ方も多いのではないでしょうか。
- SEO対策のためにはサイトマップを作成するといいってよく聞くけど、なんでサイトマップつくるとSEO対策になるの?
- クローラー、サイトマップ、robots.txtってどんな関連性があるの?
- そもそもクローラーってなに?
今回は上記のような疑問を解決するために「クローラー」、「サイトマップ」、「robots.txt」について検索の仕組みから説明をしたいと思います。
今回の記事では以下の内容について説明をします。
- 検索の仕組み
- クローラー、サイトマップ、robots.txtの役割
- SEO対策の基本的な考え
- クローラビリティについて
目次
Google検索でサイトがヒットするまでの全体の流れ
まずはSEO対策の話をする前に、検索の仕組みについて説明をしたいと思います。
Googleをはじめとする検索エンジンから検索条件にマッチしたサイトの一覧が返ってくるという動作は当たり前のように行われています。
しかし、そもそも検索エンジンはどうやってインターネットに存在する膨大なテキスト情報から検索にマッチするサイトを抽出し、ランキング化されて検索結果に出てくるのでしょうか?
まずは検索ロジックの概要を説明したいと思います。
検索ロジックの概要

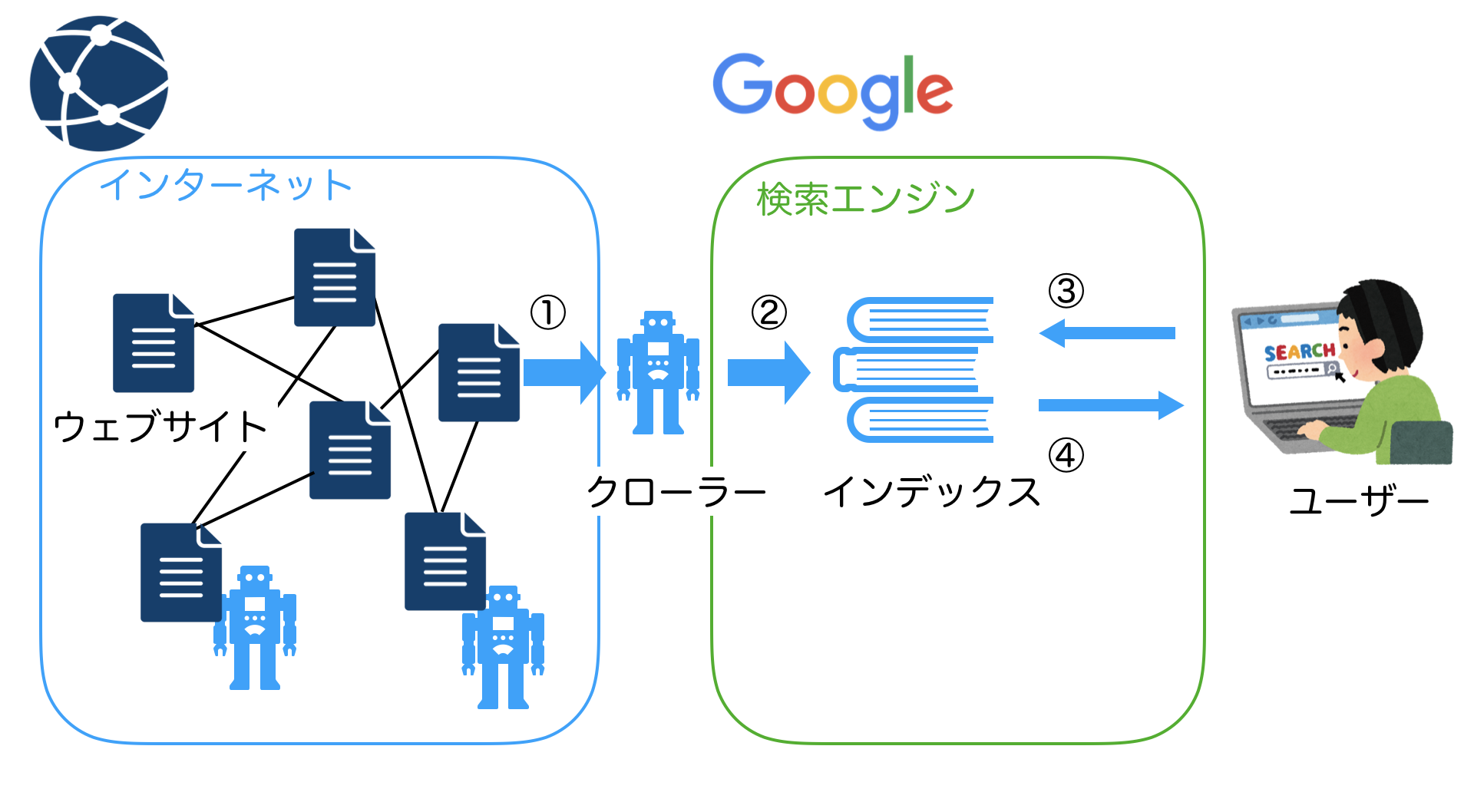
検索のロジックはざっくり説明すると以下のようになっています。
- クローラーがインターネットを巡回しウェブサイトの情報を取得する
- クローラーの情報がインデックスに保存される
- 検索エンジンがインデックスの情報を検索する
- 検索エンジンが検索結果をユーザーに返す
しかし、全てを説明すると図や内容が細かくなりすぎるので、今回は簡略的な図で説明を行なっています。
つまり、検索エンジンは検索ごとに毎回インターネットの情報を全て検索しているわけではなく、クローラーというシステムが収集してきた情報からインデックスというデータを事前に作成しており、インデックスを元に検索結果を返しています。
インターネットに存在するサイトを本に例えるならば、クローラーは世の中の本を集める役割、インデックスは集められた本を積んでおく本棚の役割をしています。そして「こういった本が欲しい」というリクエストにマッチしている本を検索エンジンは本棚から探してきます。
SEO対策と密接な関係にあるクローラー
先ほど出てきたクローラーについてもう少し詳しく説明をします。
クローラーとはインターネットを巡回し、ウェブ上に存在するサイト情報を取得してくるもののことをいい、取得した情報を検索エンジンに蓄積するという役割を持っています。
ウェブサイトの巡回する方法はサイトにあるリンクを経由することで実現しています。
クローラーが情報収集する行為をクローリングと呼びます。
クローラーはウェブサイトのリンクを経由することでインターネットを巡回しながら情報収集をするのですが、サイトに1度訪れただけで全ての情報を取得するわけではありません。
同じサイトにクローラーは何度も訪れて情報を少しずつ取得しています。
先ほども説明したように検索エンジンはインデックスの情報を元に検索結果を返します。
そして、そのインデックスはクローラーの情報を元に構築されています。
クローラーによってサイトの情報をたくさんインデックスに登録してもらえれば検索にも有利に働きます。
つまり、クローラーに自分のサイトの情報を十分に知ってもらうということが検索結果で上位になるために重要にであり、これがクローラーがSEO対策と密接な関係にある理由です。
クローラーに自分のサイトの情報をしっかりと伝えるためには、
- たくさん自分のサイトにクローラーがきてもらうという量の側面
- 自分のサイトに来たときに効率的に、そしてまんべんなく情報を取得してもらうというクローリングの質の側面
の二つの観点で対策をする必要があります。
なお、クローリングの質のことをクローラービリティなどと呼び、クローラビリティを向上させることをクロール最適化などと呼びます。
SEO対策でよく聞く、「外部からリンクが多いほうがいい」というのはクローラーが自分のサイトにくる量の問題を解決しています。
また、「内部リンクをちゃんと作成したほうがいい」、「リンク切れのリンクはないほうがいい」というのはクローラーの巡回の質を解決しています。
クローラーにサイトの構成を伝えるサイトマップ
サイトマップとは名前のままですがサイトの構造を表したものです。
クローラーはウェブサイトのリンクを経由することでサイトの巡回を行なっています。言い換えればリンクが少なかったり新しすぎるページの場合はクローリングされることが難しいです。
しかし、サイトマップを作成しサイト構造をクローラーに伝えることでサイト内に存在するクローリングしにくいページでもまんべんなく巡回をしてもらうことが可能になり、その結果クローリングの質の向上につながります。
また、サイトマップを更新したことをクローラーに伝えることでクローラーがサイトにやってくるのでクローラの量の向上にもつながります。
なお、作成したサイトマップはGoogleサーチコンソールに登録することでクローラーに情報を伝えることが可能になり、クローラーがサイト内を巡回しに来てくれるようになります。
今回はSEOに関する内容の説明のため、ユーザビリティのためのサイトマップの説明は省略します。
クローラーの巡回を制御するrobots.txt
クローラーはウェブサイト内を巡回して情報を収集するのですが1回あたりの巡回には上限があります。
ですので、ウェブサイトと一言にいってもウェブサイト内には検索でヒットしなくてもいい(クロールしなくてもいい)ページが存在します。
例えばWordPressで構築されたブログであれば管理画面(wp-adminで始まるページ)はクロールする必要がありません。
robots.txtとはサイト内のクロール対象をクローラーに伝えることでサイトの巡回を制限し、クローラビリティを向上させるためのものです。
robots.txtを正しく設定することでクローラーは効率的にサイトを巡回することができ、その結果サイト内の大事な情報がしっかりとインデックスに登録されるようになりSEO対策につながります。
ちなみに、先ほどのサイトマップの作成はSEO対策をする意味で設定することは必須ですが、このrobots.txtに関しては、大規模サイトであればちゃんと設定をする必要が出て来ますが 個人ブログのようなものであれば基本的にはrobots.txtを細かく設定する必要はないです。
まとめ
今回は検索の仕組みをベースにSEO対策で重要な「クローラー」、「サイトマップ」、「robots.txt」について説明しました。
- クローラーは検索で参照されるインデックスの情報源をインターネットから取得する役割がある。
- クローラーに対する施策として「たくさん自分のサイトにクローラーがきてもらうという量の側面」と「自分のサイトに来たときに効率的に、そしてまんべんなく情報を取得してもらうというクローリングの質の側面」がある
- サイトマップやrobots.txtなどを設定することでクローリングの質や量の改善をすることができる。